Architecture · 2026-04-08 · 17분 읽기
아키텍처 규칙 강제하기(feat MultiModule, ArchUnit, AI Agent)
- ›들어가며
- ›문제: 패키지는 나뉘어 있었지만, 경계는 없었습니다
- ›Request / Response DTO 계층별 분리
- ›Controller ↔ Service ↔ Repository 레이어 DTO 분리
- ›문제: Service 재사용이 만든 의존성 확산
- ›CouponService를 여기저기서 가져다 쓰다
- ›더 나은 방향: 도메인 단일 책임으로 분리
- ›강제할 수 있는 방법을 찾아서
- ›먼저 떠오른 것: 접근제어자
- ›방법 A. 멀티모듈 — 컴파일 시점에 강제
- ›방법 B. ArchUnit — 테스트 시점에 강제
- ›요즘 다시 의미가 커진 이유
- ›방법 C. AI Agent SKILL — 코딩 시점에 강제
- ›예상하지 못했던 과제
- ›비용과 도입 난이도
- ›세 가지 방법 비교
- ›마치며
들어가며
우리는 애플리케이션을 개발할 때 레이어드 아키텍처나 헥사고날 아키텍처와 같은 구조적 원칙을 기반으로 프로젝트를 구성합니다. 책임 분리와 의존 관계 관리라는 기술적인 장점도 분명 존재하지만, 개발을 하며 느낀 것은 아키텍처가 단순한 설계 방식이 아니라 팀이 같은 방향으로 개발하기 위한 합의이자 규약에 가깝다는 점이었습니다.
돌이켜보면 처음에는 아키텍처를 일종의 관례처럼 적용했던 것 같습니다. 좋다고 알려져 있으니 자연스럽게 도입했지만, 시간이 지나면서 왜 이 구조를 사용하고 있는지, 그리고 실제로 어떤 문제를 해결해주고 있는지를 스스로 되묻게 되었습니다. 아키텍처는 단순히 형태를 갖추는 것이 아니라, 그 장점과 의도를 이해한 상태에서 사용해야 의미가 있다는 생각이 들었습니다.
최근에는 AI Agent와 같은 도구를 활용한 개발 방식이 점차 늘어나면서, 사람뿐만 아니라 AI 역시 이해하고 따를 수 있는 아키텍처 구조는 무엇인지 고민하게 되었습니다.
하지만 아키텍처 규칙은 대부분 문서나 컨벤션으로만 정의됩니다. 개발이 이어질수록 작은 예외들이 쌓이고, 의도하지 않은 의존성이 생기며 어느 순간 왜 이런 구조가 되었는지 설명하기 어려운 코드베이스를 마주하게 됩니다.
그때부터 이런 질문을 하게 되었습니다.
규칙은 사람의 기억과 의지에 맡겨두어도 괜찮을까?
이 글에서는 업무를 진행하며 경험했던 문제점들과, 아키텍처 규칙을 문서가 아닌 코드 안에서 자연스럽게 지켜지도록 만들기 위해 시도했던 과정 — Multi Module, ArchUnit Test, 그리고 AI Agent까지의 실습을 정리해보려 합니다.
문제: 패키지는 나뉘어 있었지만, 경계는 없었습니다
아래 코드베이스를 처음 들여다봤을 때 구조는 꽤 괜찮아 보였습니다. 많은 팀에서 사용하는 전형적인 레이어드 아키텍처 형태였습니다.
com.example.project
├── controller
├── service
├── repository
└── model누가 보더라도 역할이 나뉘어 있고, 관례적으로 잘 구성된 프로젝트처럼 보였습니다.
하지만 실제 코드를 따라가 보니 전혀 다른 모습이었습니다.
Controller와 Repository가 동일한 UserModel을 함께 사용하고 있었고, Request와 Response 객체조차 분리되어 있지 않았습니다. 레이어는 나뉘어 있었지만, 경계는 존재하지 않았습니다.
문제는 요구사항 변경 순간 드러났습니다.
단순히 UserModel 하나를 수정해야 했을 뿐인데, 영향을 받는 파일이 50개가 넘었습니다. 심지어 테스트 코드도 존재하지 않아 어디까지 영향이 퍼지는지조차 확신할 수 없는 상태였습니다.
설상가상으로 @NotNull과 같은 어노테이션 기반 제약이 여러 레이어에 흩어져 있었고, 예상하지 못한 위치에서 예외가 발생하기 시작했습니다. 어떤 필드가 어디에서 채워지는지, 무엇이 nullable인지조차 추적하기 어려웠습니다.
레이어드 아키텍처의 핵심은 의존 방향을 단방향으로 유지하여 변경의 영향을 제한하는 것입니다. 하지만 하나의 모델을 모든 레이어가 공유하는 순간, 그 장점은 사실상 사라지게 됩니다.
이런 이유로 많은 팀들이 계층별 DTO를 별도로 두는 방식을 선택한다고 생각합니다. 모델을 공유하지 않고 레이어 간 경계를 명확히 함으로써, 아키텍처가 의도했던 변경 안정성과 책임 분리라는 장점을 유지하려는 시도라고 느꼈습니다.
Request / Response DTO 계층별 분리
아키텍처 규칙을 강제하기에 앞서, 먼저 현재 문제가 되었던 DTO 구조부터 계층별로 분리하는 작업을 진행했습니다.
신규 프로젝트라면 대부분 처음부터 레이어별 DTO를 나누겠지만, 실제로는 이미 운영 중인 레거시 코드베이스를 마주하는 경우가 더 많습니다. 저는 “지금 잘 동작하고 있다” 는 이유만으로 구조 개선을 미루는 것은 장기적으로 좋은 선택이 아니라고 생각합니다.
간단한 요구사항 추가 및 수정에 대해서도 기존 소스코드 구조적 문제로 사이드 이펙트가 발생한 경우가 너무나도 많았기 때문입니다 :(
신뢰할 수 있는 테스트 환경을 기반으로, 작은 단위라도 지속적으로 리팩토링하며 구조를 개선해 나가는 것이 결국 코드베이스의 안정성을 높이는 방향이라고 느꼈습니다.
기존에는 하나의 DTO를 요청과 응답에서 함께 사용하고 있었습니다. API마다 사용하는 필드가 달라 nullable 여부와 책임을 추적하기 어려웠고, 시간이 지날수록 레거시가 누적되었습니다.
요청과 응답은 목적이 다릅니다. 입력 검증 대상과 외부로 노출되는 데이터 역시 서로 다르기 때문에 DTO를 명확히 분리했습니다.
// ❌ 하나의 객체를 모든 곳에서 혼용
data class UserModel(
val id: Long?, // DB용? 응답용?
val name: String?, // nullable인지 아닌지 추적 불가
@NotNull val email: String, // 어느 레이어에서 채워지는지 모름, nullable 하게 들어가야하는 곳도 있는데 라이브러리 어노테이션 제약으로 예외가 발생하는 케이스가 있었음.
val password: String?, // 응답에 노출되면 안 되는데...
val createdAt: LocalDateTime?,
....
)
// Controller, Service, Repository 전부 UserModel 사용Controller ↔ Service ↔ Repository 레이어 DTO 분리
모든 계층에서 혼용하던 model 객체를 각 계층별 용도에 맞는 필드값만 포함하도록 수정하였습니다.
- 예제는 단순하지만, 실제 복잡한 레거시 프로젝트를 개선할때에는 기존 운영중인 소스코드 영향도를 꼼꼼히 확인하고, 테스트코드를 통해 검증하면서 개선하였습니다.
// 1. HTTP 요청 전용 (Controller 진입점)
data class CreateUserRequest(
@NotNull val name: String,
@NotNull val email: String,
@NotNull val password: String
)
// 2. Service 레이어 전달 전용 (Controller → Service)
data class CreateUserCommand(
val name: String,
val email: String,
val encodedPassword: String // Controller에서 인코딩 완료된 값
)
// 3. DB 저장 전용 (Service → Repository)
@Entity
data class UserEntity(
@Id @GeneratedValue
val id: Long = 0,
val name: String,
val email: String,
val password: String,
val createdAt: LocalDateTime = LocalDateTime.now()
)
// 4. HTTP 응답 전용 (민감 정보 제외)
data class CreateUserResponse(
val id: Long,
val name: String,
val email: String
)문제: Service 재사용이 만든 의존성 확산
비슷한 관점에서, Service가 다른 Service를 직접 주입받아 사용하는 구조 역시 장기적으로는 문제가 된다고 느꼈습니다.
처음에는 자연스러운 재사용처럼 보입니다. 이미 존재하는 비즈니스 로직을 다른 Service에서 호출하면 중복 코드를 줄일 수 있기 때문입니다.
하지만 실제 프로젝트에서는 이 방식이 예상하지 못한 의존성 전파를 만들어냈습니다.
제가 실제로 겪었던 사례를 간단한 예시로 설명해보겠습니다.
CouponService.issueCoupon() 메서드는 원래 CouponController의 쿠폰 발급 API를 위해 설계된 로직이었습니다.
// CouponController.kt — 원래 의도된 사용처
@RestController
class CouponController(
private val couponService: CouponService
) {
@PostMapping("/coupons/issue")
fun issueCoupon(@RequestBody request: IssueCouponRequest) {
couponService.issueCoupon(request.userId, request.couponCode)
}
}// CouponService.kt
@Service
class CouponService(
private val couponRepository: CouponRepository
) {
fun issueCoupon(userId: Long, couponCode: String) {
val coupon = couponRepository.findByCouponCode(couponCode)
?: throw IllegalArgumentException("존재하지 않는 쿠폰입니다.")
check(!coupon.isExpired()) { "만료된 쿠폰입니다." }
check(coupon.hasRemainingCount()) { "발급 가능 수량이 초과되었습니다." }
coupon.issue(userId)
couponRepository.save(coupon)
}
}CouponService를 여기저기서 가져다 쓰다
그런데 시간이 지나면서 다른 도메인에서도 쿠폰을 발급해야 하는 요구사항이 생겼습니다.
// RegisterService.kt — 사전가입 완료 시 쿠폰 발급
@Service
class RegisterService(
private val userRepository: UserRepository,
private val couponService: CouponService // 주입받기 시작
) {
fun completePreRegistration(userId: Long) {
// ...사전가입 처리 로직
couponService.issueCoupon(userId, "PREREGISTER_2024") // 호출
}
}// EventService.kt — 특정 이벤트 달성 시 쿠폰 발급
@Service
class EventService(
private val eventRepository: EventRepository,
private val couponService: CouponService // 여기서도
) {
fun completeEvent(userId: Long, eventId: Long) {
// ...이벤트 달성 처리 로직
couponService.issueCoupon(userId, "EVENT_REWARD_001") // 여기서도 호출
}
}겉보기에는 매우 자연스러운 구조였습니다. 쿠폰 발급 로직이 한 곳에 모여 있으니 재사용성도 좋아 보였습니다.
하지만 이 순간부터 CouponService는 더 이상 "쿠폰 도메인 전용 로직"이 아니라, 여러 도메인이 동시에 의존하는 공용 서비스가 되어버렸습니다.
그리고 문제는, 비즈니스 규칙이 변경되는 순간 드러났습니다.
// CouponService.kt — 정책 변경: 등급 검증 추가
@Service
class CouponService(
private val couponRepository: CouponRepository,
private val userService: UserService // 의존성 추가
) {
fun issueCoupon(userId: Long, couponCode: String) {
val coupon = couponRepository.findByCouponCode(couponCode)
?: throw IllegalArgumentException("존재하지 않는 쿠폰입니다.")
// 신규 정책: 등급 검증 추가
val user = userService.getUser(userId)
check(user.grade.canUseCoupon(coupon.requiredGrade)) {
"쿠폰 사용 가능한 등급이 아닙니다."
}
check(!coupon.isExpired()) { "만료된 쿠폰입니다." }
check(coupon.hasRemainingCount()) { "발급 가능 수량이 초과되었습니다." }
coupon.issue(userId)
couponRepository.save(coupon)
}
}CouponController의 API에만 등급 검증이 필요했는데, issueCoupon()을 공유하던 RegisterService와 EventService도 영향을 받게 됩니다. 사전가입 완료 보상과 이벤트 달성 보상은 등급과 무관하게 지급해야 하는데, 갑자기 등급 검증 예외가 발생하기 시작했습니다.
CouponService.issueCoupon() 변경 → 영향 범위
CouponController → 쿠폰 발급 API ✅ 의도한 변경
RegisterService → 사전가입 완료 쿠폰 지급 🔴 의도치 않은 영향
EventService → 이벤트 달성 쿠폰 지급 🔴 의도치 않은 영향더 나은 방향: 도메인 단일 책임으로 분리
EventService가 쿠폰 지급을 처리하기 위해 CouponService를 직접 알아야 할까요? 이벤트 도메인 입장에서 "어떻게 보상을 지급하는가"는 내부 관심사가 아닙니다. "보상을 지급한다"는 행위 자체만 알면 충분합니다.
핵심은 "쿠폰을 발급한다"가 아니라, 각 도메인이 보상을 지급한다는 행위에만 의존하도록 만드는 것이었습니다.
// RewardHandler.kt — 보상 지급이라는 행위를 추상화
interface RewardHandler {
fun issue(userId: Long, rewardCode: String)
}// CouponRewardHandler.kt — 쿠폰 발급 구현체
@Component
class CouponRewardHandler(
private val couponRepository: CouponRepository
) : RewardHandler {
override fun issue(userId: Long, rewardCode: String) {
val coupon = couponRepository.findByCouponCode(rewardCode)
?: throw IllegalArgumentException("존재하지 않는 쿠폰입니다.")
check(!coupon.isExpired()) { "만료된 쿠폰입니다." }
check(coupon.hasRemainingCount()) { "발급 가능 수량이 초과되었습니다." }
coupon.issue(userId)
couponRepository.save(coupon)
}
}// EventService.kt — 이제 CouponService를 직접 알지 않아도 된다
@Service
class EventService(
private val eventRepository: EventRepository,
private val rewardHandler: RewardHandler // 추상화에만 의존
) {
fun completeEvent(userId: Long, eventId: Long) {
// ...이벤트 달성 처리 로직
rewardHandler.issue(userId, "EVENT_REWARD_001")
}
}이제 CouponController용 쿠폰 발급 로직에 등급 검증이 추가되더라도, EventService는 전혀 영향을 받지 않습니다. 각 도메인이 자신의 책임만 가지고, 변경이 한 곳에서만 발생합니다.
복잡한 비즈니스 조합이 필요한 경우에는 퍼사드 패턴과 같은 조합 계층을 두는 방식도 좋은 선택이 될 수 있습니다. 다만 중요한 것은 패턴 자체가 아니라, 도메인 간 의존 방향을 의도적으로 관리하는 것이라고 생각합니다. 불필요하고 과한 디자인패턴 적용은 오히려 복잡도만 높일 수 있으니 팀 숙련도 및 구조에 따라 신중히 선택하는걸 추천드립니다.
이렇게 구조를 정리하고 나서 한 가지 불편한 생각이 들었습니다.
"지금은 내가 구조를 이해하고 있어서 괜찮다.
하지만 다음 팀원이 실수하지 않는다고 장담할 수 있을까?
그리고 3개월 뒤의 나 역시 같은 실수를 반복하지 않을까?"
패키지 구조를 정리하는 것만으로는 충분하지 않았습니다.
아키텍처는 지켜지길 기대하는 것이 아니라, 어겨지지 않도록 만들어야 하는 것이었습니다.
결국 필요한 것은 하나였습니다.
실수를 막는 구조, 즉 ‘강제’였습니다.
강제할 수 있는 방법을 찾아서
먼저 떠오른 것: 접근제어자
다들 한 번쯤은 떠올려보셨겠지만, 가장 먼저 생각한 방법은 Java/Kotlin의 접근제어자를 활용해 레이어 간 접근을 제한하는 것이었습니다.
package-private이나 Kotlin의 internal 키워드를 활용하면 의존 방향을 어느 정도 통제할 수 있지 않을까 기대했습니다.
하지만 실제로 적용해보니, 접근제어자는 어디까지나 클래스 단위의 가시성 제어에 가까웠습니다. 레이어 단위의 의존 방향까지 강제하기에는 한계가 있었습니다.
같은 모듈 안에 존재하는 이상, 패키지 구조만으로 다른 레이어를 참조하는 것을 완전히 막기는 어려웠습니다.
결국 접근제어자는 의도를 표현하는 데는 도움이 되었지만, 아키텍처 규칙을 실수 없이 지키도록 만드는 장치는 되지 못했습니다.
방법 A. 멀티모듈 — 컴파일 시점에 강제
다음으로 떠올린 방법은 레이어를 Gradle 멀티모듈로 분리하는 것이었습니다.
레이어별로 모듈을 나누고 api / implementation 의존성을 명확히 설정하면, 잘못된 방향의 의존성이 발생하는 순간 빌드 자체가 실패합니다
멀티 모듈 실습 - 헥사고날 예시 repository 의 build.gradle.kts 참고
실습은 헥사고날 아키텍처 형식으로 진행을 했었는데, 레이어드든 헥사고날이든 중요하지 않습니다. 팀 규격에 맞는 아키텍처를 모듈로 강제한다에 초점을 두면 됩니다.
// 각 모듈별로 의존하고 있는 모듈을 지정해줍니다.(의존 방향 강제)
... 생략
// controller
dependencies {
implementation("yjh.ontongsal:service")
}
// service
dependencies {
implementation("yjh.ontongsal:repository")
implementation("yjh.ontongsal:domain")
}// 실제 빌드할때 의존 관계에 따라 빌드 모듈을 지정해줄 수 있습니다.
// settings.gradle.kts
pluginManagement {
repositories {
gradlePluginPortal()
mavenCentral()
}
}
dependencyResolutionManagement {
versionCatalogs {
create("libs") { from(files("../app/gradle/libs.versions.toml")) }
}
}
rootProject.name = "service"
includeBuild("../repository")
includeBuild("../domain")실제로 적용해본 결과:
실제로 적용해보면서 느낀 점은 명확했습니다.
컴파일 시점에 규칙이 강제되기 때문에, 개발자가 실수로 의존 방향을 어기는 상황 자체가 거의 발생하지 않았습니다. 빌드가 통과했다는 사실 자체가 “아키텍처 규칙을 지켰다” 는 의미가 되었습니다.
다만 멀티모듈 도입은 생각보다 가벼운 선택은 아니었습니다.
- 모듈을 어떻게 나눌 것인가
- 어떤 레이어를 독립시킬 것인가
- 팀이 모듈 구조를 지속적으로 유지할 수 있는가
- 레거시 시스템에 모듈화를 적용할 수 있는가
이 질문들은 예상보다 훨씬 어려웠고, 실제로 컨퍼런스에서도 반복적으로 등장하는 주제라는 점이 이해되었습니다.
컴파일 시점 강제라는 장점은 매우 강력했지만, 그 외의 장점은 모듈화를 했을때의 재사용성 정도라고 생각하지만, 프로젝트마다 다른 구조에 대해 재사용하기 위해 어떻게 구조를 갖춰야할지 고민하고, 팀 숙련도에 맞춰야 한다는게 더 큰 비용이라는 생각이 들었습니다.
그래서 개인적으로는 멀티모듈을 무조건적인 정답이라기보다는, 컴파일 강제가 필요한 경우에 사용하면 좋을법한 전략적인 도구라고 생각합니다.
| 항목 | 평가 |
|---|---|
| 강제 확실성 | ⭐⭐⭐⭐⭐ (컴파일 에러) |
| 도입 비용 | 높음 |
| 팀 전제 조건 | 멀티모듈 구조 설계 능력 |
| 추천 상황 | 신규 프로젝트, 숙련된 팀 |
방법 B. ArchUnit — 테스트 시점에 강제
ArchUnit은 아키텍처 규칙을 테스트 코드로 명시하고 검증할 수 있게 해주는 라이브러리입니다.
예를 들어
“Service 레이어는 Controller 레이어에 의존하면 안 된다”
같은 규칙을 문서가 아니라 실행되는 코드로 정의할 수 있습니다.
testImplementation("com.tngtech.archunit:archunit-junit5:1.4.1")import com.tngtech.archunit.core.importer.ImportOption
import com.tngtech.archunit.junit.AnalyzeClasses
import com.tngtech.archunit.junit.ArchTest
import com.tngtech.archunit.lang.ArchRule
import com.tngtech.archunit.lang.syntax.ArchRuleDefinition.classes
import com.tngtech.archunit.lang.syntax.ArchRuleDefinition.noClasses
@AnalyzeClasses(
packages = ["yjh.ontongsal.restapi"],
importOptions = [ImportOption.DoNotIncludeTests::class],
)
class ArchitectureTest {
@ArchTest
val domainHasNoApplicationDependency: ArchRule =
noClasses()
.that().resideInAPackage("..service..")
.should().dependOnClassesThat()
.resideInAPackage("..controller..")
.`as`("서비스 계층은 컨트롤러 계층에 의존하지 않아야 한다")
}규칙을 한 번 정의해두면 이후 모든 테스트 실행 과정에서 자동으로 검증됩니다. 구조를 위반하면 테스트가 실패하며, 어떤 클래스가 규칙을 깨뜨렸는지도 명확히 알려줍니다.
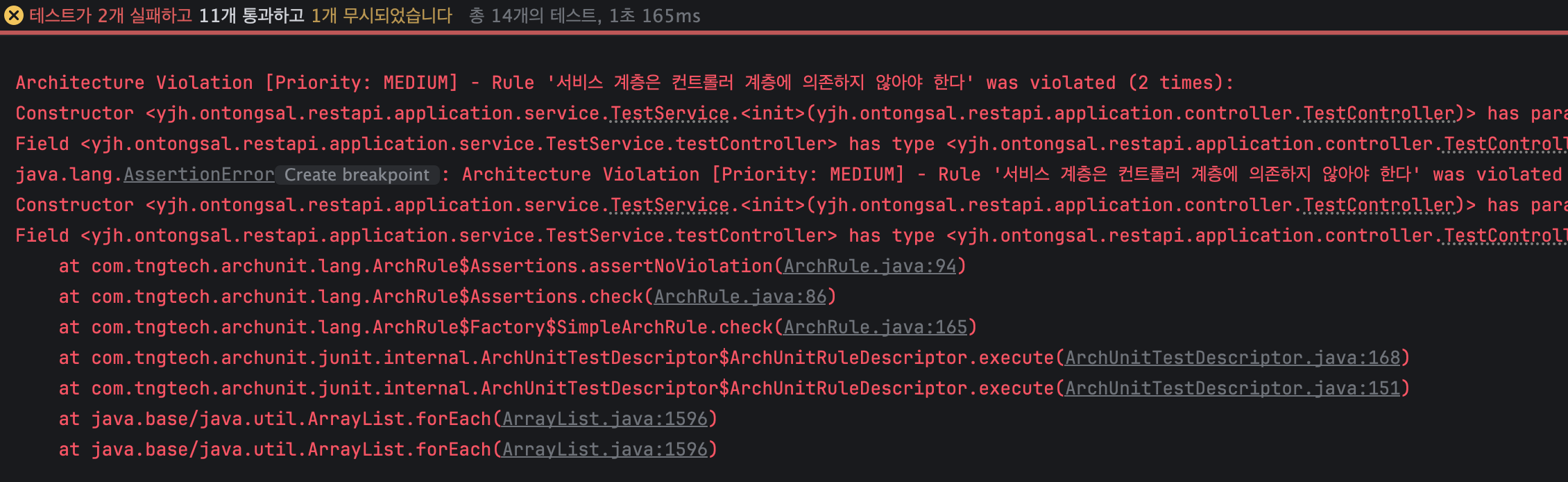
실제로 적용해본 결과:
멀티모듈처럼 프로젝트 구조를 크게 바꾸지 않아도 아키텍처 규칙을 자동으로 검증할 수 있다는 점이 가장 큰 장점이었습니다.
다만 전제 조건이 하나 있습니다.
👉 테스트가 실행되는 환경이 반드시 있어야 합니다.
- 테스트를 작성하지 않는 팀
- CI 파이프라인이 없는 프로젝트
에서는 ArchUnit 규칙이 존재하더라도 사실상 동작하지 않습니다. 파일은 있지만 아무도 검사하지 않는 상태가 됩니다.
요즘 다시 의미가 커진 이유
개인적으로는 AI가 코드를 작성하기 시작하면서 테스트의 의미가 조금 달라졌다고 느꼈습니다.
이전에는 테스트가 기능이 제대로 동작하는지 확인하는 역할에 가까웠다면, 지금은 프로젝트의 구조가 무너지지 않았는지를 감시하는 역할도 중요해졌다고 생각합니다.
AI는 빠르게 코드를 만들어주지만, 프로젝트가 가진 아키텍처 의도까지 항상 이해하고 지켜주지는 않습니다. 조금만 방심하면 레이어 의존성이 조용히 섞여 들어가기도 합니다.
그래서 ArchUnit을 사용했을 때 가장 좋았던 점은, 아키텍처 규칙을 사람이 계속 기억하지 않아도 테스트가 대신 확인해준다는 점이었습니다.
테스트를 실행하는 순간, 프로젝트 구조를 자동으로 리뷰받는 느낌이었습니다.
| 항목 | 평가 |
|---|---|
| 강제 확실성 | ⭐⭐⭐⭐ (테스트/CI 실패) |
| 도입 비용 | 중간 |
| 팀 전제 조건 | 테스트 작성 문화, CI 파이프라인 |
| 추천 상황 | 테스트 문화가 있는 팀 |
방법 C. AI Agent SKILL — 코딩 시점에 강제
현재 많은 팀에서 Claude Code 와 같은 AI Agent 도구들을 적극적으로 사용하고 있습니다. 저 또한 AI 를 활용하여 개발 생산성을 향상시킬 여러가지 챌린지들을 시도해보는 중인데요, AI가 코드를 생성하는 시점에 아키텍처 규칙을 함께 인식하게 할 수 있도록 여러 방면으로 시도해보는 중입니다.
저는 Claude Code 를 기준으로 실습을 진행 해보았습니다.(Gemini 등 다른 AI Agent 도 어느정도 비슷한 기능들을 표준처럼 제공하기 때문에 적용해볼 수 있을 것 이라고 생각합니다.)
1. CLAUDE.md, SKILLS, HOOK 등 AI Agent 가 동작해야할 명령들을 잘 구조화해서 Context 로 주입하기.
AI 도구는 프로젝트 루트의 규칙 파일을 컨텍스트로 읽습니다. 여기에 의존 방향 규칙, DTO 분리 원칙, 금지된 패턴 등을 명시하면, AI가 코드를 생성할 때 이 규칙을 따릅니다.
// CLAUDE.md 아키텍처 규칙 작성 예시
# 아키텍처 규칙
## 레이어 의존 방향 (반드시 준수)
Controller → Service → Repository 단방향만 허용
## 금지 패턴
- Controller에서 Repository 직접 참조 금지
- Service에서 다른 Service 직접 주입 금지
- 공통 비즈니스 로직은 UseCase 또는 Handler로 분리
## DTO 분리 원칙
- HTTP 요청/응답: XxxRequest, XxxResponse (controller 패키지)
- 레이어 간 전달: XxxCommand, XxxResult (service 패키지)
- DB 전용: XxxEntity (repository 패키지)
- 하나의 객체를 여러 레이어에서 혼용하지 않는다
## 코드 생성 시 체크리스트
1. 새 클래스를 만들기 전에 UseCase 인터페이스를 먼저 확인할 것
2. 의존 방향이 위 규칙을 따르는지 확인할 것
3. DTO가 레이어 경계를 넘어가고 있지 않은지 확인할 것2. UseCase 명세를 AI의 스코프 경계로 활용
단순히 규칙을 텍스트로 주입하는 것에서 한 단계 더 나아가, UseCase 인터페이스와 테스트 코드 자체를 AI의 컨텍스트로 활용하는 방법을 시도해보았습니다.
UseCase는 👉 “이 시스템이 무엇을 할 수 있는가” 를 정의하는 명세입니다.
저는 이를 AI가 따라야 할 설계 경계로 활용했습니다.
AI가 새로운 기능을 구현할 때 먼저 UseCase를 확인하도록 유도하면,
임의로 새로운 구조를 만들기보다 이미 정의된 설계 내부에서 기능을 확장하게 됩니다.
결국 UseCase는 단순한 인터페이스를 넘어, AI의 작업 범위를 제한하는 설계 가이드라인 역할을 하게 됩니다.
// UseCase 인터페이스 + 테스트 코드가 AI 컨텍스트로 작동하는 예시
// ArticleUseCase.kt — AI가 "무엇을 할 수 있는가"를 파악하는 명세
interface ArticleUseCase {
fun write(actor: Actor, boardId: TargetId, title: ArticleTitle, content: ArticleContent): Long
fun update(actor: Actor, articleId: TargetId, title: ArticleTitle, content: ArticleContent): Long
fun delete(actor: Actor, articleId: TargetId)
fun findArticle(articleId: TargetId): Article
fun findAll(targetId: TargetId, page: Int, pageSize: Int): Page<Article>
fun findAllInfiniteScroll(targetId: TargetId, lastArticleId: Long?, pageSize: Int): Slice<Article>
}
// ArticleUseCaseTest.kt — 명세가 곧 AI의 구현 범위이자 경계
class ArticleUseCaseTest {
@Test
fun `게시글 작성 - 정상 작성`() {
// given
val actor = Actor(userId = 1L)
val boardId = TargetId(10L)
val title = ArticleTitle("첫 번째 게시글")
val content = ArticleContent("내용입니다.")
// when
val articleId = articleUseCase.write(actor, boardId, title, content)
// then
assertThat(articleId).isPositive()
}
@Test
fun `게시글 수정 - 작성자가 아니면 예외`() {
val actor = Actor(userId = 999L) // 작성자가 아닌 사용자
val articleId = TargetId(1L)
assertThrows<AccessDeniedException> {
articleUseCase.update(actor, articleId, ArticleTitle("수정"), ArticleContent("수정 내용"))
}
}
@Test
fun `게시글 목록 조회 - 페이지네이션`() {
val targetId = TargetId(10L)
val result = articleUseCase.findAll(targetId, page = 0, pageSize = 20)
assertThat(result.content).hasSizeLessThanOrEqualTo(20)
}
@Test
fun `게시글 무한스크롤 - lastArticleId 이후 항목만 반환`() {
val targetId = TargetId(10L)
val lastArticleId = 50L
val result = articleUseCase.findAllInfiniteScroll(targetId, lastArticleId, pageSize = 10)
assertThat(result.content).allMatch { it.id < lastArticleId }
}
}[기획] > [UseCase 도출] > [UseCase 로부터 발생가능한 비즈니스 혹은 도메인 규칙들을 테스트코드로 작성] 과 같은 흐름으로 구현할 수 있고 UseCase와 테스트 코드로부터 검증 SKILL 파일을 자동 생성하는 COMMAND를 만들어어서 사용할 수 도 있습니다.
// SKILL/COMMAND 파일 예시
# SKILL: validate-architecture
## 실행 조건
코드 변경이 발생했을 때 자동 실행
## 수행할 검증 항목
### 1. UseCase 변경 감지
- UseCase 인터페이스가 변경된 경우
→ 구현체(ServiceImpl)가 인터페이스를 올바르게 구현하는지 확인
→ 관련 테스트 코드가 존재하는지 확인
### 2. 의존 방향 검증
변경된 파일에서 아래 패턴을 탐지하면 경고:
- controller 패키지에서 repository 패키지 import
- service 클래스에서 다른 service 클래스를 생성자 주입
- XxxRequest / XxxResponse 객체가 service 패키지 내부에 존재
### 3. 위반 감지 시 출력 형식
[ARCHITECTURE VIOLATION]
파일: {파일명}
위반 규칙: {규칙명}
위반 내용: {구체적인 위반 내용}
권장 수정: {수정 방향 제안}이를 Git hook과 연동하면, UseCase가 변경될 때마다 SKILL 파일이 자동으로 업데이트됩니다.
Git hook 연동 스크립트 예시
#!/bin/sh
# .git/hooks/pre-commit
CHANGED_FILES=$(git diff --cached --name-only --diff-filter=ACM | grep "UseCase.kt$")
if [ -n "$CHANGED_FILES" ]; then
echo "UseCase 변경 감지 → SKILL 파일 자동 업데이트"
for file in $CHANGED_FILES; do
echo "처리 중: $file"
# UseCase 인터페이스에서 메서드 목록 추출
METHODS=$(grep -E "fun [a-zA-Z]+" "$file" | sed 's/.*fun //' | sed 's/(.*//')
# SKILL 파일 업데이트
SKILL_FILE=".claude/skills/validate-architecture.md"
{
echo "# 자동 생성: $(date)"
echo "## 검증 대상 UseCase: $file"
echo "## 정의된 메서드"
echo "$METHODS" | while read -r method; do
echo " - $method"
done
} >> "$SKILL_FILE"
git add "$SKILL_FILE"
done
echo "SKILL 파일 업데이트 완료"
fi실제로 적용해본 결과:
AI Agent 기반 접근을 팀 개발 흐름에 적용해보면서 가장 크게 느낀 변화는 아키텍처 규칙이 ‘문서’가 아니라 ‘실행 규칙’이 되었다는 점이었습니다.
기존에는 아키텍처 가이드나 코드 컨벤션을 문서로 공유하더라도, 새로운 기능이 빠르게 추가되는 과정에서 규칙이 점점 흐려지는 문제가 있었습니다. 특히 AI를 활용해 코드 생성 속도가 빨라질수록, 구조적 일관성이 무너질 가능성도 함께 커졌습니다.
AI Agent에 CLAUDE.md, SKILL, HOOK 등을 통해 규칙을 컨텍스트로 주입하자, 코드를 생성하는 순간부터 다음과 같은 변화가 나타났습니다.
- Controller → UseCase → Repository 의존 방향이 자연스럽게 유지됨
- DTO 혼용이나 레이어 침범 코드가 눈에 띄게 감소
- 신규 기능 구현 시 패키지 구조가 자동으로 정렬됨
- 리뷰 과정에서 “구조 지적”보다 “도메인 논의”에 집중 가능
특히 인상적이었던 부분은 AI의 작업 스코프를 UseCase 명세로 제한할 수 있었다는 점입니다.
특히 UseCase 와 테스트 코드를 기준으로 AI의 작업 범위를 제한하자, AI가 새로운 구조를 만들어내기보다 기존 설계 안에서 확장하는 방식으로 동작했습니다.
이는 마치 멀티모듈 구조가 컴파일 타임에 의존성을 강제하는 것처럼, AI 환경에서도 설계 구조를 지속적으로 유지하도록 만드는 효과를 주었습니다.
결과적으로,
설계가 사람이 지키는 규칙에서 → AI가 함께 유지하는 시스템으로 전환되는 경험을 할 수 있었습니다.
예상하지 못했던 과제
물론 모든 문제가 한 번에 해결된 것은 아니었습니다.
AI Agent는 전달된 컨텍스트에 매우 민감하게 반응합니다. CLAUDE.md나 SKILL 파일의 규칙이 모호하거나 빠져 있으면, AI는 쉽게 의도와 다른 구조의 코드를 생성했습니다.
결국 깨달은 점은 하나였습니다.
AI에게 규칙을 전달하는 일 자체가 또 하나의 아키텍처 설계 작업이라는 것.
이 과정에서 얻은 인사이트는 다음과 같습니다.
아키텍처 문서는 사람이 아니라 AI가 이해할 수 있게 작성해야 한다 규칙을 정의하는 것보다 AI가 실제로 지키고 있는지 검증하는 과정이 더 중요하다 이제 AI Agent 자체도 테스트 대상이 된다
그래서 이후에는 SKILL 기반 검증 로직을 추가해, AI가 생성한 코드 역시 자동으로 검사하도록 구성해볼 생각입니다.
비용과 도입 난이도
AI Agent 기반 검증은 토큰 비용이 발생한다는 단점이 있습니다.
다만 실제로 적용해보니, 변경된 파일 범위 내에서만 검증하도록 제한하면 비용 부담은 생각보다 크지 않았습니다.
오히려 다음과 같은 장점이 더 크게 느껴졌습니다.
기존 코드베이스 수정 없이 즉시 도입 가능 멀티모듈 전환이나 대규모 리팩토링 없이 구조 통제 가능 레거시 프로젝트에도 점진적으로 적용 가능
특히 이미 운영 중인 프로젝트에서도 부담 없이 시작할 수 있다는 점에서, 현실적인 선택지라는 인상을 받았습니다.
| 항목 | 평가 |
|---|---|
| 강제 확실성 | ⭐⭐⭐ (AI 판단에 의존) |
| 도입 비용 | 낮음 |
| 팀 전제 조건 | AI 코딩 도구 사용 |
| 추천 상황 | 빠른 도입이 필요한 팀, 레거시 프로젝트 |
세 가지 방법 비교
| 멀티모듈 | ArchUnit | AI Agent SKILL | |
|---|---|---|---|
| 강제 시점 | 컴파일 | 테스트 (CI) | 코딩 중 |
| 확실성 | 매우 높음 | 높음 | 중간 |
| 도입 비용 | 높음 | 중간 | 낮음 |
| 팀 전제 조건 | 모듈 구조 설계 숙련도 | 테스트 문화 + CI | AI 도구 사용 |
| 레거시 적용 | 어려움 | 가능 | 즉시 가능 |
| 추천 상황 | 신규 프로젝트, 숙련 팀 | 테스트 문화 있는 팀 | 빠른 도입 필요 시 |
셋 중 하나를 정답처럼 선택하기보다, 팀이 지금 당장 실행할 수 있는 방법부터 시작하는 것이 현실적이라고 느꼈습니다.
마치며
세 가지 방법을 적용해보면서 공통적으로 느낀 점이 있습니다.
아키텍처 규칙을 지키는 일은 팀원의 의지나 숙련도의 문제가 아니라, 시스템이 얼마나 일관되게 강제하고 있는가의 문제라고 생각합니다.
일정이 바쁘거나, 새로운 팀원이 합류하거나, 충분한 컨텍스트 없이 개발이 진행되는 순간에도 구조가 유지되려면 규칙은 사람의 기억이 아니라 시스템 안에 있어야 한다고 느꼈습니다.
이번 실습을 통해 정리한 점은 다음과 같습니다.
구조가 먼저 정리되어 있어야 강제도 가능하다고 생각합니다. 강제 방식은 팀 상황에 맞게 선택하는 것이 현실적이라고 느꼈습니다. UseCase 명세는 사람과 AI 모두에게 좋은 작업 경계가 된다고 생각합니다.
아직 진행 중인 실험이지만, 아키텍처 검증 역시 점점 자동화의 영역으로 이동하고 있다고 생각합니다.
좋은 아키텍처는 문서로 유지되지 않는다고 생각합니다. 코드가 작성되는 순간부터 지속적으로 검증될 때만 유지된다고 느꼈습니다.
규칙은 강제될 때 비로소 규칙이 된다고 생각합니다.
읽어주셔서 감사합니다.
'Architecture ' 카테고리의 다른 글
- 이 카테고리에 다른 글이 없습니다.